Adjacency tables |

|

|
|
Adjacency tables |
|
|
Adjacency tables |
|
|
|
Adjacency tables |
|
|
Adjacency tables provide additional control over dependency rules when they point between different stages, push-backs or other pre-defined groupings within the deposit. Adjacency tables cater for two different, but related problems, as follows:
| • | a database level is used to classify the deposit into stages, but the generic rule sets cannot determine the stage where each successor occurs. |
| • | generic dependency rule sets create the correct dependencies over most of the deposit, but also create some unwanted rules on the boundaries between groups. |
As the approach taken in each case differs, they will be discussed separately.
When a hierarchical database level is used to classify the deposit into groups, generic dependency rules cannot determine the predecessors group if it is not in the same group as the successor, even though its physical location can be found in the normal way.
For example, in a project with a Stage/Bench/Northing/Easting database structure, a generic rule can be used to find the predecessors Bench, Northing and Easting, but not its Stage. If the predecessor is not in the same stage as the successor, the generic dependency rule will not be able to locate it and it will therefore assume the predecessor is missing.
In this situation, an adjacency table can be used to instruct XPAC to test for the predecessor in other stages, if it is not found in the same stage as the successor. The table is used to indicate which stages are adjacent to one another and which stages are independent of each other.
To assign an adjacency table to a dependency rule set, the Adjacency Table tab must be selected when the rule set is being edited. Ticking the Use Adjacency Table checkbox activates the adjacency table and displays a grid where the adjacency data must be entered.
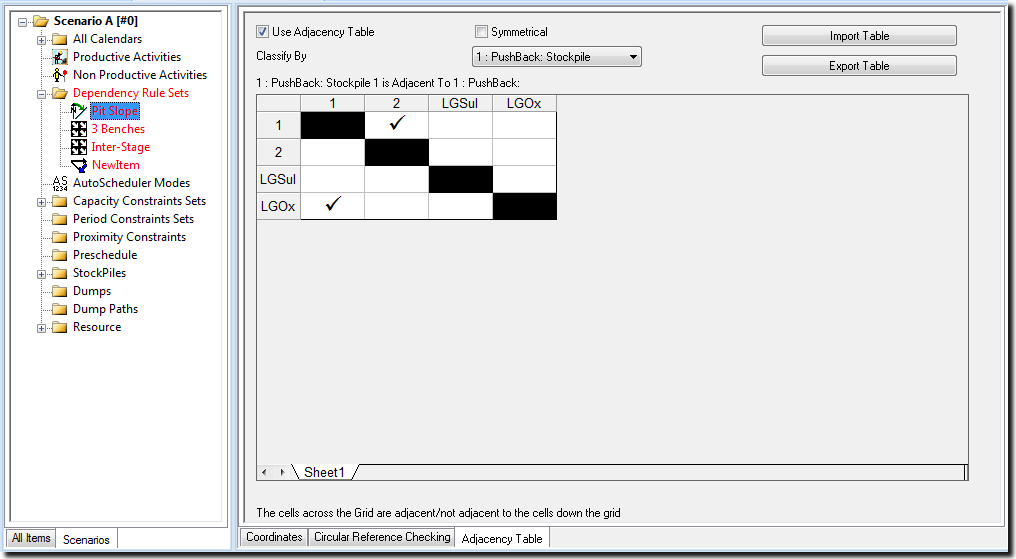
The Classify By drop down box allows the user to choose what database level should be used as the basis for classifying the deposit. Although a database field can also be chosen from this list, it would not be appropriate in this situation. The first database level is assigned by default, but the user can select any other database level for this purpose.
Once the level that will be used to classify the deposit has been selected, the AutoScheduler will scan the entire database and construct a list of each group of records within the database.This is based on the level names rather than the APIL numbers, and if the same level name occurs more than once in different parts of the database (for example, if Stage 1 occurs in several pits), they will be treated as different groups.
Once the list of groups has been determined, the square grid will be re-sized so there is a row and column for every group found. The names of the groups are displayed as titles for the rows and columns. The set up of the adjacency table is now complete and the user must define which groups are adjacent to one another.
Each row in the table represents a group to which the successor may belong, whilst the columns represent the groups that may be adjacent to it. As a group cannot be adjacent to itself, the cells along the diagonal are not available.
To indicate that a number of groups are adjacent to group A, the user must select the cells in the row titled group A. You should only select columns used to represent the adjacent groups. XPAC will display a tick mark in a selected cell and remove the tick mark if the cell is deselected.
The adjacency data does not have to be symmetrical, and group A can be adjacent to group B without group B being adjacent to group A. However, if the Symmetrical check box is ticked, whenever an entry is added to the table, the inverse entry will be added automatically. This will not effect entries that existed in the table before the checkbox was selected.
When a dependency rule set is applied, it will search for the predecessor in the same group as the successor. If this search fails, it will then search for the block in each adjacent group. A dependency will only be created if the predecessor is found in one of these groups.
When a pit has been sub-divided into a number of stages or push backs, it is normal for these to be mined independently of one another. However, generic dependency rules will not be aware of this staged approach and can therefore create some undesirable dependencies.
For example, if a pit is being mined in two stages, blocks in stage 1 cannot be dependent on stage 2, but blocks in stage 2 should be dependent on blocks in stage 1. When generic dependency rule sets are used to create the dependencies (particularly relative bearing rule sets) it can sometimes be difficult to prevent (or filter out) the rules that would make stage 1 dependent on stage 2.
Adjacency tables make this process very straightforward and provides the user with total control over which dependencies are created. The table is used in a similar manner to that described in the previous section, but with some minor differences.
If the deposit has been classified into groups using a level in the database, the user should not indicate that two stages are adjacent if dependencies should not be created between them. The AutoScheduler will then fail to detect the predecessor (because it will not be in an adjacent stage) and the dependency will not be created.
However, it is common to use a field in the database to classify the deposit into stages, as this allows the allocation of blocks to stages to be changed very easily. In this situation, the predecessor will always be found, regardless of the stage the block occurs in.
To overcome this problem the adjacency table can be used as a filter. The user should first select the field that must be used in the Classify By list box and then indicate which pits should be considered adjacent by ticking the appropriate cells in the grid. This process is identical to that described in the previous section.
Any field can be used as the basis of the classification, but care should be taken when it is selected, particularly in large projects. If a grade field was selected accidentally, XPAC will identify thousands of unique groups and an enormous grid would be required.
When the dependency rule set is applied, it will determine the dependencies as normal, but before creating the rules it will check which stages the successor and predecessor belong to. If they occur in the same stage or if the stages have been flagged as adjacent, the dependency will be created as normal. But if they occur in different stages that that have not been flagged as adjacent, the dependency will not be created.
Although adjacency tables were introduced to overcome the two problems described above, they have also been used in other situations where some of the dependencies a rule set would normally create must be filtered out. The ability to specify a Predecessor Filter range (added in release 7.4) will reduce the reliance on adjacency tables for some applications.